PEPR: Privileged Event-based Predictive Regularization for Domain Generalization
CVPR 2026 Findings
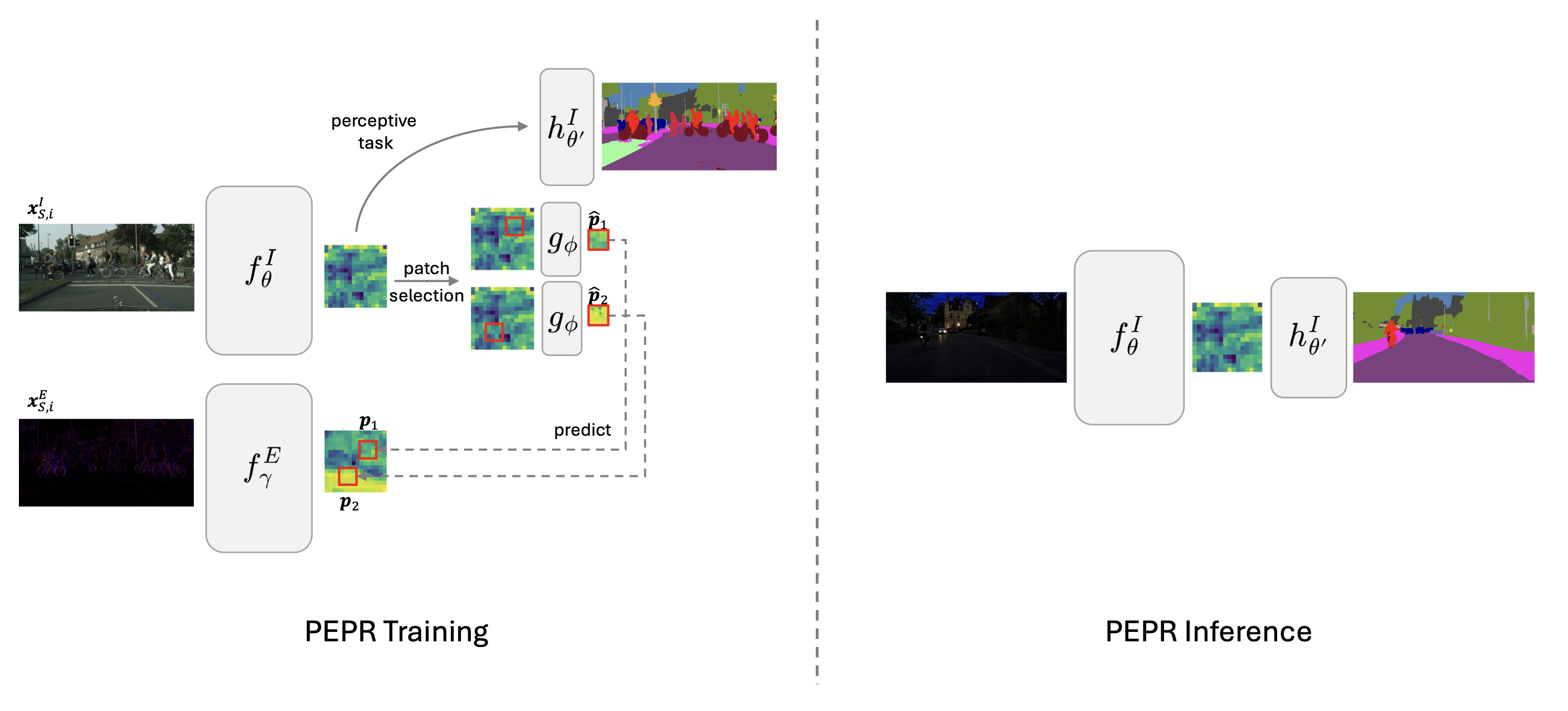
Prediction over Alignment
Instead of forcing dense RGB features to directly match sparse event outputs, PEPR trains the RGB encoder to predict event-derived latent targets via a lightweight predictor module.
Events as Privileged Information
Event cameras act as a training-only supervisory signal. They provide domain-invariant cues during training and are completely discarded after training — no paired data needed at deployment.
RGB-only Deployment
At test time, PEPR runs with the standard RGB model — no event camera, no additional sensors, no extra inference modules. The robustness is baked into the encoder weights.
During training, PEPR combines four components: an RGB encoder (backbone), a task prediction head (segmentation or detection), a privileged event encoder, and a predictor module that maps RGB latents to event latent targets. The total loss combines the standard task loss with the prediction loss between RGB-predicted and event-derived representations. After training, the event encoder and predictor are discarded.
Patch Selection Mechanism
A core challenge in cross-modal predictive learning is that event cameras produce sparse outputs: most of the spatial grid carries no signal at any given moment. Supervising every RGB patch against an empty event target would flood the predictor with uninformative gradients and destabilize training.
PEPR addresses this with a patch selection mechanism: only the spatial patches where the event stream is active — i.e., where events actually fired — are selected as prediction targets for the RGB encoder. Concretely, the event representation is divided into non-overlapping patches and those with sufficient event density are retained. The predictor then aligns the corresponding RGB patches only at those locations, concentrating the supervision signal where the event modality is informative. This selective alignment makes the training loss meaningful and prevents the RGB encoder from being pulled toward trivial or noisy targets.

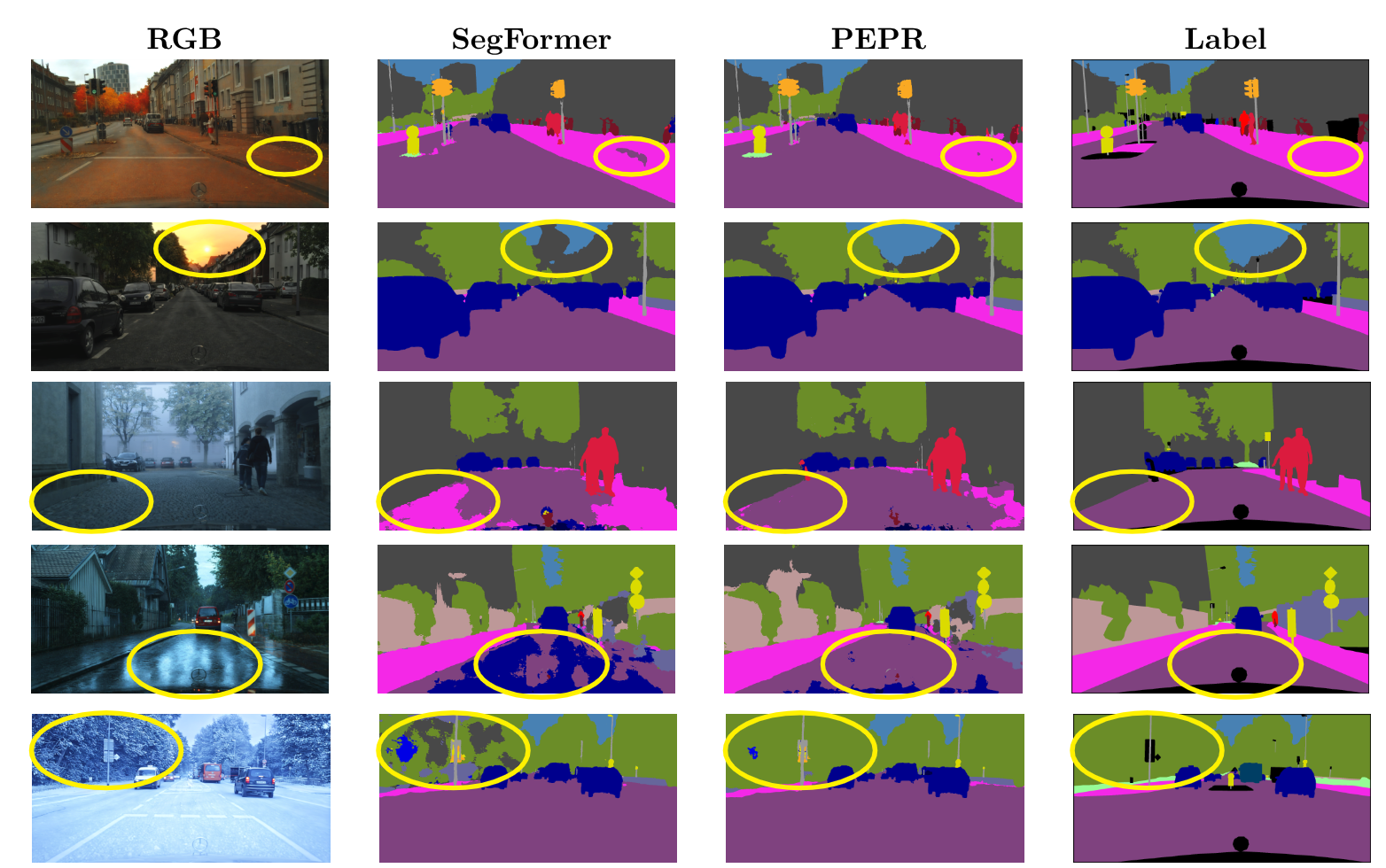
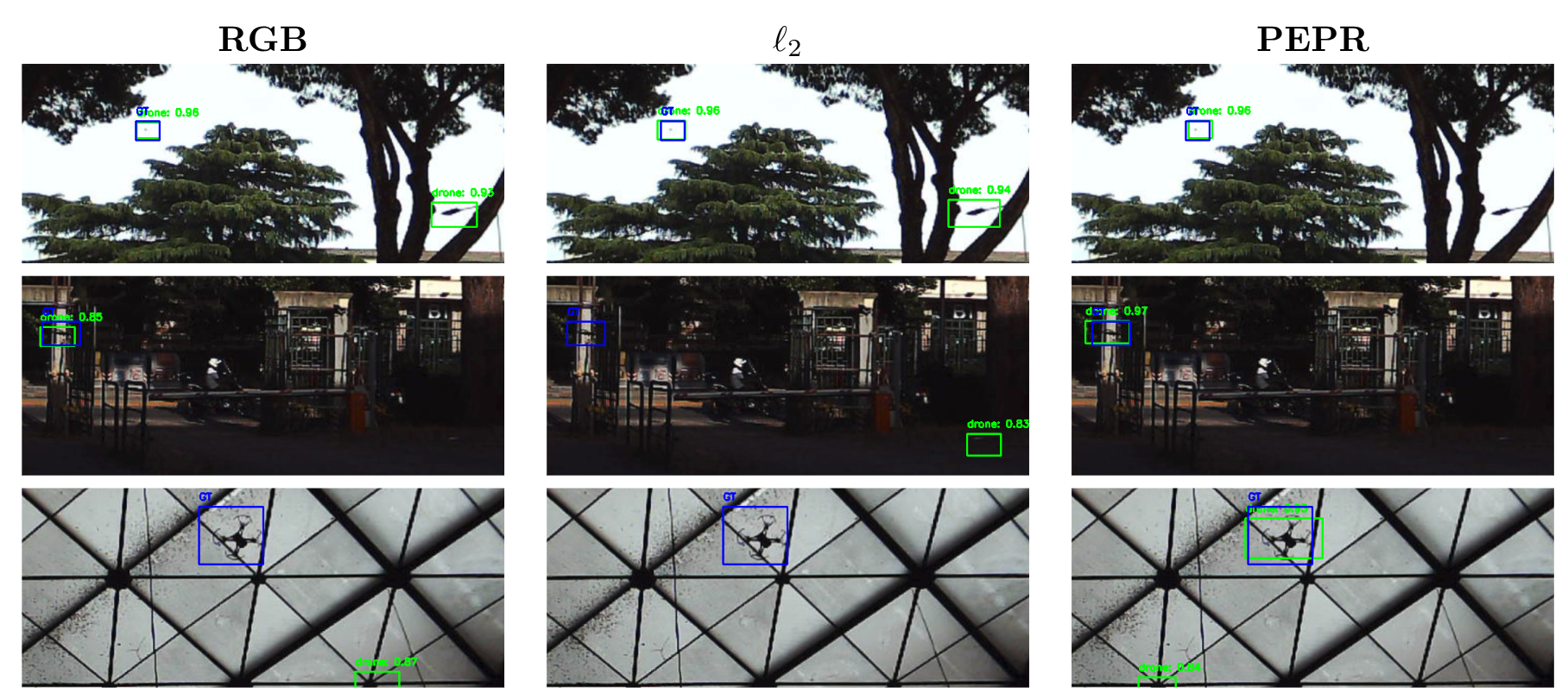
PEPR is evaluated on three benchmarks spanning semantic segmentation and object detection under domain shift, using the FRED, DSEC, Hard-DSEC-DET, Cityscapes, and Cityscapes Adverse datasets. A selection of key results is shown below; many additional experiments and ablations are reported in the full CVPR 2026 Findings paper.

@inproceedings{magrini2026pepr,
title = {PEPR: Privileged Event-based Predictive Regularization for Domain Generalization},
author = {Magrini, Gabriele and Becattini, Federico and Biondi, Niccolò and Pala, Pietro},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
note = {Findings},
year = {2026},
arxiv = {2602.04583}
}